




1. Introduction▲
1-A. DSL ?▲
DSL est sigle de Domain-Specific Language (en anglais), c'est-à-dire Langage Spécifique au Domaine. Il s'agit généralement d'un « petit » langage de programmation dédié à un domaine d'activité spécifique. Il est conçu pour apporter des solutions aux problèmes soulevés dans un domaine particulier et donc est ainsi difficilement réutilisable dans d'autres domaines. C'est pourquoi ce type de langage de programmation se distingue des GPL (General Purpose Language) tels que Java, C, C++… dont le but de ces derniers est de proposer des solutions à tout type de problème solvable par ordinateur. Ce qui peut ne pas être la manière la plus optimale. Les concepts et les notations d'un DSL doivent alors être choisis pour être suffisamment proches des objets manipulés dans le domaine traité. Notons que les problèmes du domaine traité sont naturellement ceux pouvant être résolus par ordinateur.
1-B. Xtext ? À quoi ça peut servir ?▲
Xtext est un framework développé sur Eclipse et permettant d'implémenter votre propre DSL textuel ou même de mettre sur pied un langage de programmation générique (un GPL). Il fonctionne sur une JVM (Machine Virtuelle Java) et est constitué de plusieurs API qui vous permettent de décrire les différents aspects du langage que vous voulez créer et propose une implémentation complète de ce langage. Notons que le langage développé sera alors un langage qui s'appuie et qui surcouche le langage Java. C'est-à-dire que les objets offerts par ce framework sont complètement des objets Java et le développement du compilateur de votre langage sera alors écrit en Java.
Xtext peut servir entre autres à proposer des solutions dans les domaines tels que : les systèmes embarqués, l'automobile, les appareils mobiles, l'automatique, les jeux vidéo, etc.
Notons aussi que les langages développés via Xtext peuvent selon son tutoriel être définis non seulement avec le langage Java, mais aussi d'autres langages tels que C, C++, C# objective C, Python et Ruby. De plus, une fois que le DSL est mis en œuvre , son utilisation devient indépendante de la JVM.
1-C. Qu'offre Xtext par rapport aux technos Java les plus utilisées ?▲
D'après la littérature, il existe deux technologies Java très populaires pour la mise en œuvre de DSL ou de GPL. Ce sont : JavaCC et ANTLR.
JavaCC (Java Compiler Compiler) et ANTLR (ANother Tool for Language Recognition) sont ainsi des technos permettant de mettre en œuvre un langage de programmation et ont existé avant Xtext. Elles permettent à travers la grammaire que l'on a définie pour le langage, de générer automatiquement les objets (lexer, parser : constructeur de l'arbre syntaxique abstraite, contrôleur de type…) nécessaires pour sa mise en œuvre. Le développeur devait alors utiliser ces objets pour développer son compilateur ou l'interpréteur. Puis la phase de création de l'IDE du langage correspondait à une étape où le développeur devait se taper une grande partie du code à la main. Xtext est un framework innovateur intégré à Eclipse et qui offre une simplicité dans le développement de DSL et/ou GPL. Il surcouche ANTLR qui s' occupe de la fabrication des objets ci-dessus cités (lexer, parser…), mais aussi offre un éditeur Eclipse (dont nous devons continuer le développement) du nouveau langage avec déjà de nombreux opérateurs par défaut tels : la complétion de code, la coloration syntaxique, l'analyse syntaxique, etc.
Pour résumer, nous disons que Xtext est un framework libre développé sur Eclipse et qui intègre tout ce qui est nécessaire pour le développement d'un DSL ou d'un GPL de façon complète : c'est-à-dire de la spécification de la grammaire du DSL, en passant par le développement de son compilateur, jusqu'au développement de l'IDE Eclipse du DSL. De plus, puisque Xtext utilise EMF (Eclipse Modeling Framework), il offre des packages très riches que nous n'avons qu'à exploiter dans nos développements. Xtext offre également une grammaire initiale que l'on peut étendre (utiliser) dans la définition de la nôtre. Cette grammaire initiale offre des éléments importants comme la gestion des espaces, des retours chariot, tabulation, des chaines de caractères, des entiers, etc.
N.B. : il existe plusieurs autres technologies concourant au développement de langages de programmation telles que : lex/flex, yacc/bison (en C) et aussi JFlex/JCup, SableCC ou encore Tatoo, etc.
1-D. Installation d'Eclipse Xtext▲
L'installation d'Eclipse Xtext est simple. Il suffit de télécharger le fichier zip sur le site itemis des développeurs d'Xtext à l'adresse http suivante : http://xtext.itemis.com/xtext/language=en/36553/downloads. Notons qu'il existe plusieurs versions correspondant à différents systèmes d'exploitation. Téléchargez donc la version qui correspond à votre cas. Lorsque le téléchargement est terminé, il suffit de copier le fichier zip sur votre disque dur à l'endroit où vous désirez. Après l'avoir dézippé, dans le répertoire qui se crée, on constate la présence de plusieurs dossiers et fichiers parmi lesquels eclipse.exe. Il suffit alors de double-cliquer sur cette icône pour démarrer Eclipse Xtext.
Notons pour finir que l'on peut créer un raccourci de cet exécutable (sur son bureau par exemple) en cliquant à droite sur eclipse.exe, puis en choisissant envoyer vers et enfin bureau (créer un raccourci). Ceci pour s'affranchir d'une perte de temps lors du démarrage d'Eclipse Xtext.
2. Premier projet avec Xtext▲
Nous allons apprendre à créer un projet Xtext sous Eclipse Helios. Nous utilisons la version 1.0.2 de Xtext.
2.1- Double-cliquer sur l'icône eclipse.exe dans le répertoire correspondant ou sur le raccourci que vous avez créé sur votre bureau.
2.2- la fenêtre suivante apparaît :
|
|

Il faut indiquer à Eclipse Xtext, le répertoire de vos projets (le workspace). Un exemple ici est le répertoire D:\Backup\Mes Documents\ProjetsEclipseXTEXT. Après avoir choisi votre workspace, cliquer sur OK.
2.3- Dans la fenêtre qui s'ouvre, cliquer sur l'icône à l'extrême gauche pour ouvrir la fenêtre de choix du type de projet à créer. Dans l'aperçu suivant, cette icône est encadrée d'un rectangle rouge :
|
|
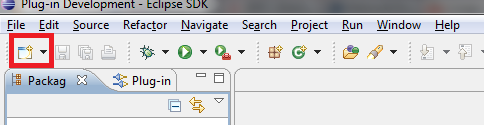
Notons que l'on peut aussi cliquer sur la petite flèche à côté de cette icône pour dérouler un menu dans lequel on va choisir l'onglet Project. On peut aussi réaliser l'opération précédente en passant par la procédure suivante : File-->New-->Project.
2.4- Dans la fenêtre du choix du type de projet qui s'ouvre, dérouler l'arbre nommé XText, puis choisir Xtext project et enfin cliquer sur next :
|
|

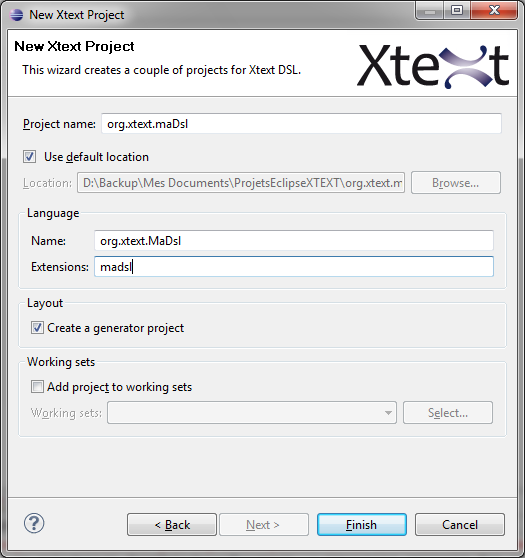
2.5- Dans la fenêtre qui apparaît, donner un nom à votre projet dans le champ project name. Exemple : maDsl. ( N.B. Ce nom doit commencer par une lettre minuscule). Puis, donner un nom à votre langage. Exemple : MaDsl (N.B. Ce nom doit commencer par une lettre majuscule). Enfin, nommer l'extension des fichiers où seront enregistrés les programmes de votre langage. Exemple : madsl. Cliquer sur finish, pour terminer la création. Il est mieux de créer notre projet dans le package de base org.xtext fourni par Xtext. Ce qui fait que lors de la saisie du project name, nous devons effacer ce qui est écrit par défaut et saisir comme nom de projet : org.xtext.maDSL. Cela est pareil pour le nom de votre langage. De plus, il vaut mieux laisser les cases à cocher telles qu'elles sont. Enfin, il serait quand même intéressant de choisir des noms significatifs pour des projets réels et sérieux et non des choses comme maDsl.
Voici l'aperçu de cette fenêtre :
|
|
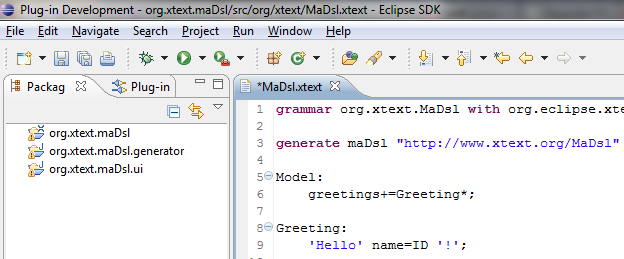
2.6- Dans la fenêtre Eclipse qui apparaît, on voit le projet Xtext qui est créé et qui est composé de trois parties (org.xtext.maDsl, org.xtext.maDsl.generator et enfin org.xtext.maDsl.ui).
|
|
Notre premier projet Xtext a été créé avec succès. Nous allons voir dans la section suivante, comment implanter la grammaire d'un DSL en prenant un exemple simple.
3. Implanter une grammaire pour votre DSL▲
Nous allons dans cette section apprendre à développer la grammaire d'un DSL sous Eclipse Xtext. Pour cela, il nous faut partir d'un exemple. Nous allons donc dans le paragraphe suivant proposer un exemple simple pour comprendre comment on procède. De plus, notons que les grammaires écrites sous Xtext s'appuient sur la forme étendue de Backus-Naur (EBNF).
3-A. Description de notre DSL▲
Supposons que nous voulions construire un DSL qui concerne le domaine de la statistique (les statisticiens). Supposons que nous avons des statisticiens qui étudient des populations de tout genre et qui au terme de leurs travaux disposent :
- des différentes modalités de la population étudiée ;
- des effectifs de chaque modalité.
Ils aimeraient faire des études sur cette population qui peuvent d'ailleurs être très complexes. Pour faire simple, supposons que leurs études se limitent au calcul de la moyenne, de la variance, de l'écart type et du mode de cette population.
Pour rester dans un contexte simpliste, nous allons supposer que les modalités de la population sont quantitatives et ne peuvent être que des entiers et/ou des réels (et donc pas de modalité qualitative ou encore par intervalle). De plus, nous supposons que le nombre de modalités ne doit pas être très grand au point de ne pas pouvoir être saisissables à la main.
Exemple : supposons qu'une étude statistique vise à comprendre des phénomènes sur les notes d'un examen d'informatique d'une salle de classe d'un effectif total de 20 étudiants.
Voici dans le tableau suivant ce qui pourrait être recensé comme données des statisticiens :
|
Modalités (notes) |
08 |
11 |
12 |
14 |
15 |
Total |
|
Effectifs (étudiants) |
5 |
6 |
4 |
3 |
2 |
20 |
Notons que si nous avons une série statistique de modalités xi et d'effectifs ni, tels que l'effectif total est n = ![]() , alors :
, alors :
La moyenne est égale à : 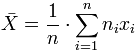
La variance notée V est égale à : 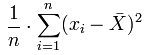
L'écart type est égal à la racine carrée de la variance V.
Le mode est égal à la modalité ayant le plus grand effectif.
Nous voulons écrire des programmes statistiques simples qui vont permettre de calculer ces valeurs à chaque fois pour une série statistique donnée.
Nous voulons que les programmes de notre DSL aient la structure simple suivante :
|
program nom_du_programme |
Illustration :
|
program calculMoyenne |
Notons que contrairement à cet exemple hyperacadémique, dans la réalité, les langages peuvent être divers et complexes. Notre but étant juste d'utiliser cet exemple pour montrer comment travailler avec Xtext.
3-B. Développement de la grammaire du DSL sous Xtext▲
Pour écrire la grammaire de notre DSL, nous devons ouvrir le premier projet parmi les trois qui ont été précédemment créés (dans notre cas, il s'agit du projet org.xtext.maDsl), puis double-cliquer sur le fichier ayant l'extension .xtext (dans notre cas MaDsl.xtext). En général, après création de votre projet Xtext, ce fichier s'ouvre automatiquement. Au cas où il ne s'ouvre pas ou s'ouvre mal, il faut l'ouvrir manuellement.
Aperçu :
|
|
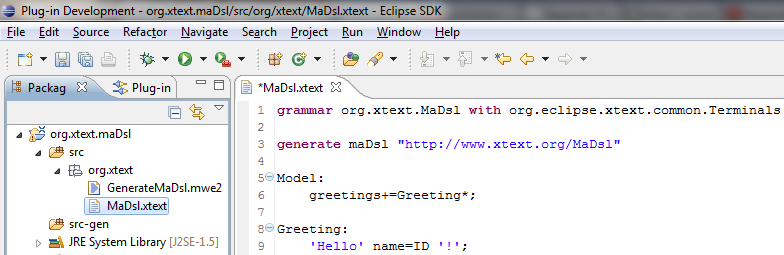
Avant de commencer à écrire notre grammaire, on constate que le fichier MaDsl.xtext s'ouvre avec une grammaire exemple. Nous allons profiter de cela pour gagner quelques prérequis avant de nous lancer.
- La première ligne : grammar org.xtext.MaDsl with org.eclipse.xtext.common.Terminals représente la déclaration de notre grammaire nommée MaDsl et le fait qu'elle étende (qu'elle utilise) la grammaire initiale généreusement offerte par Xtext (org.eclipse.xtext.common.Terminals). Cette grammaire offerte par Xtext déclare pour nous, un ensemble d'éléments importants et d'ailleurs souvent très nuisant lorsque nous devons le faire par nous-mêmes. Nous n'aurons alors dans notre propre grammaire qu'à utiliser les éléments qu'elle nous offre sans nous poser de question. Les éléments offerts par cette grammaire initiale de Xtext sont de façon non exhaustive : les chaines de caractères (représentés par le terminal ID), les entiers (représentés par le terminal INT), les espaces, tabulations, retour chariot, les commentaires, etc. Notons que l'on n'est pas obligé d'utiliser cette grammaire initiale de Xtext, mais nous pensons qu'elle est importante pour écrire des grammaires simples à comprendre et rapidement.
Pour voir à quoi ressemble cette grammaire offerte par Xtext, maintenir la touche Ctrl enfoncée, et cliquer sur le texte suivant : org.eclipse.xtext.common.Terminals dans votre fenêtre Eclipse.
Aperçu :
|
|
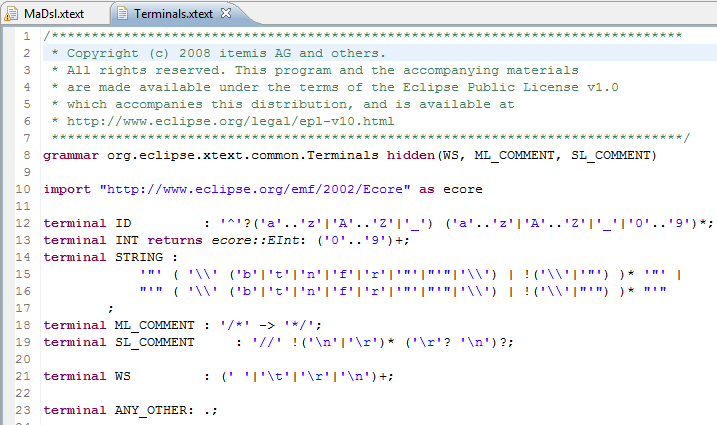
- La deuxième ligne : generate maDsl « http://www.xtext.org/MaDsl » est très importante pour Xtext pour la génération des objets importants pour le développement du langage et qui sont issus de la grammaire. Mais nous n'entrons pas dans les détails ici. Toujours laisser cette deuxième ligne intacte.
- Puis nous avons les lignes suivantes qui représentent une ébauche de la façon dont nous devons écrire nos grammaires :
|
Model : |
Cette grammaire permet d'écrire zéro ou une liste de phrases du genre : Hello world !, Hello Georges !, etc. dans un IDE dédié au langage régi par cette grammaire. Dans cette grammaire, Model et Greeting représentent des non-terminaux. Model représente l'axiome de la grammaire parce qu'il s'agit du tout premier non terminal, la racine. On voit dans cette grammaire que Model se dérive en greetings+=Greeting* et Greeting à son tour se dérive en 'Hello' name=ID '!'. Nous allons voir ci-dessous ce que représentent greetings et name. Dans la règle de production Model: greetings+=Greeting*, l'étoile qui est à droite de Greeting signifie que Model se dérive zéro ou plusieurs fois au non terminal Greeting. Pour cela on utilise le symbole += pour marquer cette dérivation multiple. Si par exemple, Model se dérivait en une seule fois en Greeting, on écrirait : Model : greetings=Greeting. Puis, nous avons Greeting qui se dérive en une phrase qui commence par Hello suivi d'une chaine de caractères et se termine par un point d'exclamation. Notons qu'une règle de production sous Xtext se termine toujours par un point-virgule.
Lorsque Xtext voit ainsi une telle grammaire écrite, il génère entre autres objets (lexer, parser…), des classes Java (interfaces et implémentations) correspondant à chaque non-terminal ayant fait intervenir une variable (cf. greetings, name). Ce sont ces classes encapsulées comme objets dans l'arbre syntaxique généré par Xtext, que nous utiliserons pour écrire le compilateur ou l'interpréteur du langage. Nous allons voir à la fin de ce document comment générer ces classes. À l'intérieur de chacune de ces classes, nous disposons des getters et des setters correspondant à la structure des règles de production de la grammaire. Pour l'exemple précédent, Xtext va nous générer les interfaces des classes Model et Greeting qui ressemblent à ceci :
|
public Model extends EObject{ |
Public Greeting extends EObject{ |
On voit bien que la classe Model permet de récupérer une liste d'objets Greeting, alors que la classe Greeting permet de récupérer la chaine de caractères name qui avait alors une valeur inconnue dans la grammaire. De même, c'est la variable greetings déclarée dans la grammaire qui est utilisée pour fabriquer le getter de la classe Model (getGreetings()). EList représente le type List de java.util sous Xtext (cf. EMF) et est manipulé de la même façon en utilisant un itérateur. EObject représente le model de nos programmes, l'arbre syntaxique abstrait…
Lorsque nous voulons donc écrire une grammaire sous Xtext, si nous voulons qu'un non-terminal soit représenté par une classe Java lors de la génération, nous devons dans la définition de sa règle de production utiliser des variables. Xtext va donc utiliser ces variables pour générer des getters et des setters.
Exemple : soit une règle de production (r).
- Si (r) s'écrit X : y=ID ; alors, Xtext générera une classe X contenant un getter et un setter pour la variable y de type String (cf. terminal ID). De même si on remplace ID par un non terminal quelconque (ex. : Z), alors y sera de type Z.
- Si (r) s'écrit X : y?='bonjour' ; alors, la variable y est de type booléen et Xtext va générer une classe X avec une méthode de test booléenne sur y qui vaut true lorsque le mot bonjour est saisi et false sinon, puis une méthode setter sur y.
- Si (r) s'écrit X : (y=Z)? alors cette règle signifie que X se dérive zéro ou une fois en Z. C'est-à-dire que X se dérive en Z ou en l'élément vide (ou en rien). Xtext génère une classe X exactement comme au point 1.
- Si (r) s'écrit X : (y+=Z)* équivalent à X : y+=Z* alors cette règle signifie que X se dérive zéro ou plusieurs fois en Z. La variable y est de type une liste de Z. Xtext va générer une classe X contenant le getter de y qui représente une liste de Z. La parenthèse permet de factoriser l'écriture, parce que (r) peut par exemple s'écrire, X : (y+=Z | p+=W)* où | représente l'opérateur de choix. C'est-à-dire que X se dérive zéro ou plusieurs fois en Z ou en W et pas en Z et W en même temps.
- Si (r) s'écrit X : (y+=Z)+ alors, c'est exactement la même chose qu'au point 4. à la différence que X se dérive ici une ou plusieurs fois en Z et non plus zéro ou plusieurs fois.
Notons que nous pouvons aussi combiner certains de ces opérateurs. Par exemple, si nous écrivons la règle X : (y=Z) (p=W)? (g+=L)*, cela voudrait dire que X est un non terminal qui se dérive en une seule fois en Z suivi d'un W optionnel et enfin de zéro ou une liste de L.
Maintenant que nous avons les prérequis pour écrire notre grammaire, nous devons saisir dans le fichier MaDsl.xtext la grammaire suivante :
|
grammar org.xtext.MaDsl with org.eclipse.xtext.common.Terminals |
N.B. : Faire attention au copier/coller dans ce fichier .xtext qui peut souvent générer des erreurs. Nous allons maintenant, ligne par ligne, essayer de décrypter cette grammaire pour la comprendre. Les deux premières lignes de cette grammaire ont déjà été expliquées.
1.
|
import « http://www.eclipse.org/emf/2002/Ecore » as ecore |
http://www.eclipse.org/emf/2002/Ecore est un package EMF contenant aussi le package EPackage de gestion des types de données (cf. EList). Cette ligne signifie donc qu'on importe ce package dans notre grammaire sous le nom ecore. L'utilisation de ce package dans notre grammaire est faite à la dernière ligne du fichier MaDsl.xtext.
2.
|
PROGRAMME : |
Il s'agit de la première règle de production de notre grammaire. PROGRAMME est donc l'axiome de notre grammaire, la racine de l'arbre syntaxique. Cette règle stipule que notre programme se dérive en cinq parties : un PREAMBULE, une déclaration de DEBUT, une déclaration des MODALITES, une déclaration des EFFECTIFS, un RETURN pour retourner le résultat du calcul souhaité et une déclaration de fin de programme END. Tous ces non-terminaux seront à leur tour définis dans les lignes qui suivent. Notons que pour bien assurer la lisibilité de notre grammaire, nous avons décidé d'écrire en majuscules les non-terminaux et les variables qu'utilise Xtext dans la génération des classes en minuscules. Exemple : l'écriture pream=PREAMBULE signifie que la classe PROGRAMME qui sera générée, contiendra un getter et un setter de la variable pream de type PREAMBULE. L'opérateur d'optionalité « ? » est utilisé ici pour permettre à ce qu'un PROGRAMME se dérive en ces cinq parties ou en rien. Ceci afin de permettre qu'un programme vide soit aussi un programme valide. Si nous l'omettons, nous allons constater que lorsque nous ouvrons « l'IDE » de notre langage (cf partie 3.4), il s'ouvre avec une erreur. Ceci parce qu'il s'attend spontanément à voir ces cinq parties saisies. Vous pouvez faire l'expérience en l'omettant.
3.
|
PREAMBULE : |
Cette ligne stipule que notre non terminal PREAMBULE précédent se dérive en un terminal appelé program (qui représente ainsi un mot-clé du langage. Et par généralisation, tous les mots entre quottes sont des mots-clés de notre langage) suivis d'une chaine de caractères (de valeur à saisir par l'utilisateur) qui va représenter le nom de notre programme.
4.
|
DEBUT : |
Ici le non-terminal DEBUT se dérive en un mot-clé appelé begin. Cela veut dire que dans nos programmes, après avoir déclaré le préambule, nous devons obligatoirement écrire le mot begin.
5.
|
MODALITES : |
Cette ligne signifie que le non terminal MODALITES se dérive :
- en un terminal appelé mod, suivi du terminal : (un deux-points ). mod et le deux-points n'a pas été mis dans la même paire de quottes pour rendre le langage flexible. Car faire ainsi, permet à l'utilisateur de mettre autant d'espaces entre mod et le deux-points ;
- suivi d'une liste de réels représentant les différentes modalités de la série statistique. Sachant qu'une étude peut donner lieu à une seule modalité, nous sommes amenés à déclarer une première modalité obligatoire à écrire par l'utilisateur (premiereModalite=REEL), suivi d'une liste optionnelle d'autres modalités séparées par des virgules. Ceci par l'écriture : ((',' autreModalite+=REEL)+)*. REEL est un non-terminal représentant les nombres réels et doit être défini plus tard ;
- tout cela enfin se terminant par un point-virgule.
6.
|
EFFECTIFS : |
Cette ligne est pareille en explication que la précédente. Mais concerne plutôt les effectifs correspondant à chaque modalité.
7.
|
RETURN : |
Cette règle stipule que le non-terminal RETURN se dérive en un mot-clé return suivi d'un non-terminal RETOUR et enfin d'un point-virgule. Nous allons voir dans ce qui suit en quoi se dérive RETOUR.
8.
|
RETOUR : |
Le non-terminal RETOUR se dérive en quatre mots-clés à prendre chacun au choix. Soit ecarttype, soit moyenne, soit… Cela veut dire que dans nos programmes après avoir renseigné les modalités et les effectifs, si nous écrivons return moyenne, le programme est sensé calculer la moyenne arithmétique de cette série statistique et nous retourner le résultat.
9.
|
END : |
Puis, nous avons la règle qui fait appel au non-terminal END qui se dérive en la chaine de caractères (mot-clé) end pour clôturer le programme.
Il nous reste maintenant à définir les règles utilisées pour définir les nombres réels dans notre grammaire.
10.
|
REEL : |
Cette règle stipule que le non terminal REEL se dérive en un terminal appelé DOUBLE qui représente en fait l'ensemble des nombres réels que nous allons définir. Nous allons voir dans la dernière ligne suivante comment cela est défini sous Xtext.
11.
|
terminal DOUBLE returns ecore::EDouble: '-'?INT ('.' INT)? ; |
Pour définir un ensemble de données à partir d'un autre sous Xtext, la procédure à suivre est comme dans le tableau précédent. Cette ligne est rattachée à la ligne « import « http://www.eclipse.org/emf/2002/Ecore » as ecore », où ecore représente le nom de ce package dans notre grammaire. Comme nous voulons que cet ensemble de données s'appelle DOUBLE, nous l'écrivons entre les mots-clés : terminal et returns. Puis nous écrivons le terme ecore::EDouble qui permet de convertir l'écriture '-'?INT ('.' INT)? en réel. EDouble est une instance de EDataType de EMF qui contient quasiment, sinon tous les types de données que nous connaissons. L'écriture '-'?INT ('.' INT)? représente ainsi les réels dans notre langage. Cette écriture signifie qu'un nombre réel peut ou non commencer par un signe négatif, suivi d'un entier, et enfin suivi d'une partie optionnelle qui représente la partie décimale de ce réel. Cette partie est optionnelle parce qu'un réel est avant tout un entier.
Nous avons ainsi terminé l'écriture de la grammaire de notre DSL destiné au domaine de la statistique. Nous allons maintenant apprendre pour terminer cet article à générer les classes Java correspondant aux éléments de notre grammaire, puis comment exécuter notre projet pour éditer un programme.
3-C. Génération de code▲
Pour générer les classes Java liées aux non-terminaux de notre grammaire ainsi que le parseur et autres objets Java de notre DSL, voici la procédure à suivre : dans le projet org.xtext.MaDsl, cliquer à droite sur le fichier GenerateMaDsl.mwe2, puis dans le menu qui s'ouvre, choisir Run As et enfin cliquer sur 1 MWE2 Workflow. Si la compilation se passe bien, c'est que votre grammaire ne comporte aucune erreur.
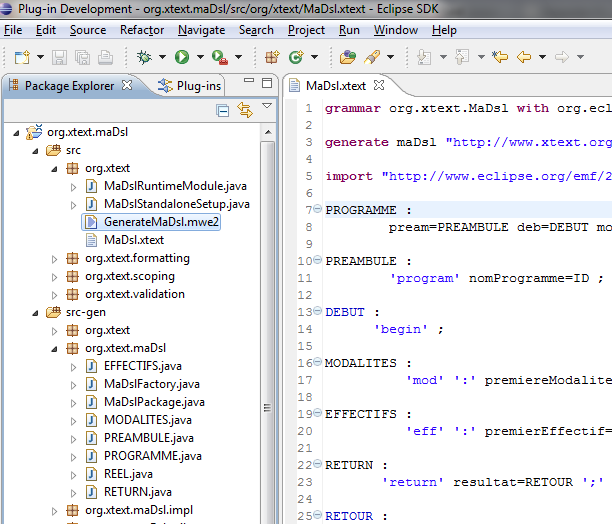
Voici un aperçu des classes générées à l'issue de l'opération précédente :
Les classes MaDslRuntimeModule.java, MaDslStandaloneSetup.java ont été automatiquement générées ainsi que celles du dossier src-gen/org/xtext/maDsl. On peut reconnaître qu'elles ont le même nom que les non-terminaux utilisés dans la grammaire. Il s'agit des interfaces dont nous parlions précédemment. Leur implémentation se trouve dans le package org.xtext.maDsl.impl.
|
|
3-D. Exécution du projet et test de saisie d'un programme▲
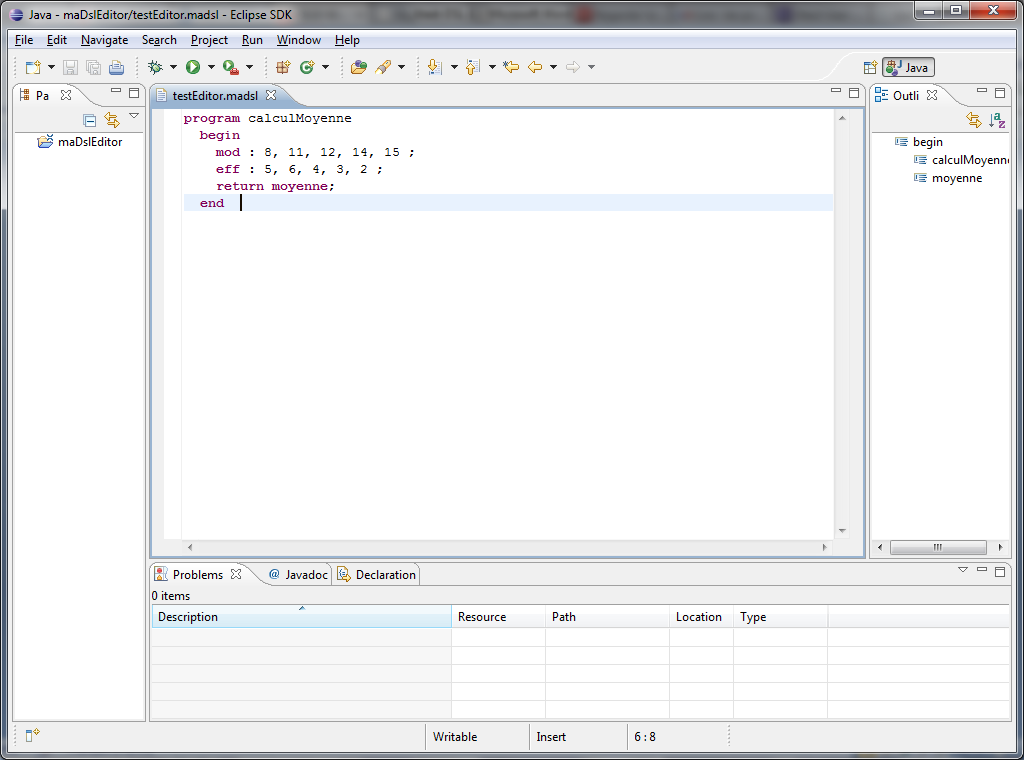
Pour exécuter le projet, nous devons cliquer à droite sur le premier des trois projets (org.xtext.maDsl), dans le menu qui s'ouvre, choisir Run As, puis 1 Eclipse Application. Une nouvelle fenêtre Eclipse va se lancer et s'ouvrir. Dans cette nouvelle fenêtre Eclipse, nous allons créer un nouveau projet de type général (File-->Project-->New-->General-->Project). Renseigner le nom du projet dans la fenêtre qui s'ouvre (ex : maDslEitor). Une fois ce projet créé, cliquer droit sur ce projet, puis choisir New dans le menu qui apparait, choisir File dans le nouveau menu qui apparait également. Une fenêtre s'ouvre, dans cette fenêtre saisir dans le champ File name le nom d'un fichier du projet maDslEditor avec l'extension .madsl (exemple : testEditor.madsl). Cliquer sur OK. Eclipse va se rendre compte qu'il s'agit d'un fichier d'édition des programmes votre DSL et va nous demander s'il importe Xtext dans ce projet. Choisissons Yes. Une fois le fichier apparu dans notre projet maDslEditor, double-cliquer pour l'ouvrir. Il représente pour l'instant l'IDE de notre DSL. Nous pouvons maintenant saisir des programmes de notre DSL. Nous allons constater qu'Xtext souligne les erreurs syntaxiques commises dans ces programmes. Ce qui veut dire qu'il embarque dans cet éditeur un analyseur syntaxique pour notre langage.
Voici pour finir l'aperçu de l'édition de deux programmes, l'un comportant une erreur syntaxique et l'autre sans erreur. On peut aussi remarquer la coloration syntaxique offerte.
|
|

|
|
4. Conclusion▲
Au terme de ce travail, nous avons abordé la notion de DSL et nous avons appris comment mettre sur pied un DSL à travers le framework Xtext. Nous avons également évoqué d'autres technologies aidant à la création des DSL. Par un exemple banal, nous avons appris à écrire une grammaire d'un langage sous Xtext et comment exécuter notre projet jusqu'à la réalisation de tests pour voir si ce projet Xtext réalise ce que nous attendons du langage.
Ce qui m'a motivé dans l'écriture de cet article vient du fait de la très faible documentation sur l'utilisation de ce framework balaise, si ce n'est le User Guide de Xtext lui-même qui est d'ailleurs très long et en anglais. J'ai alors décidé de rédiger cet article afin de partager ma petite expérience avec ceux qui ont des projets pouvant porter dans le domaine de la réalisation d'un DSL ou d'un GPL.
5. Perspectives▲
Dans de prochains articles, nous verrons comment faire pour utiliser les classes et autres objets que nous génère Xtext pour écrire le compilateur ou l'interpréteur de notre langage. Puis, nous verrons si nous parvenons à le réaliser nous-mêmes, comment développer la partie ui de notre projet Xtext (ex : org.xtext.maDsl.ui) afin de créer le propre IDE de notre langage.
6. Remerciements▲
Je voudrais remercier monsieur Mickael BARON, Ingénieur de Recherche dans le Laboratoire d'Informatique Scientifique et Industrielle (LISI/ENSMA), pour son encouragement à la rédaction de cet article et pour sa relecture. Un merci aussi à Aldian et à : Mahefasoa, Claudeleloup de Developpez.com pour leurs relectures technique et orthographique respectivement.
7. Références▲
Xtext User Guide : http://www.eclipse.org/Xtext/documentation/1_0_0/xtext.html#DSL.